
TL;DR
We needed a bunch of annotated game data, we were in a hurry, and we made it happen as fast as we possibly could. It was tricky, we broke a lot of things, and it worked. Here's what we did, what worked and what we broke.
The Problem
It turns out you can make a surprisingly good world model by recording yourself playing one game for a few hours, but if you want an actually good world model you need a lot more data, you need it to be a lot more diverse, and you need to be able to verify quality. To get that done, you need good metadata for the game and system configuration and you need to be able to actually browse the data to verify if it’s what you need.
All of this amounts to infrastructure: It’s really clear what you want to happen, and you know what each individual piece would look like, but it’s tricky to actually make it all happen.
Our Solution
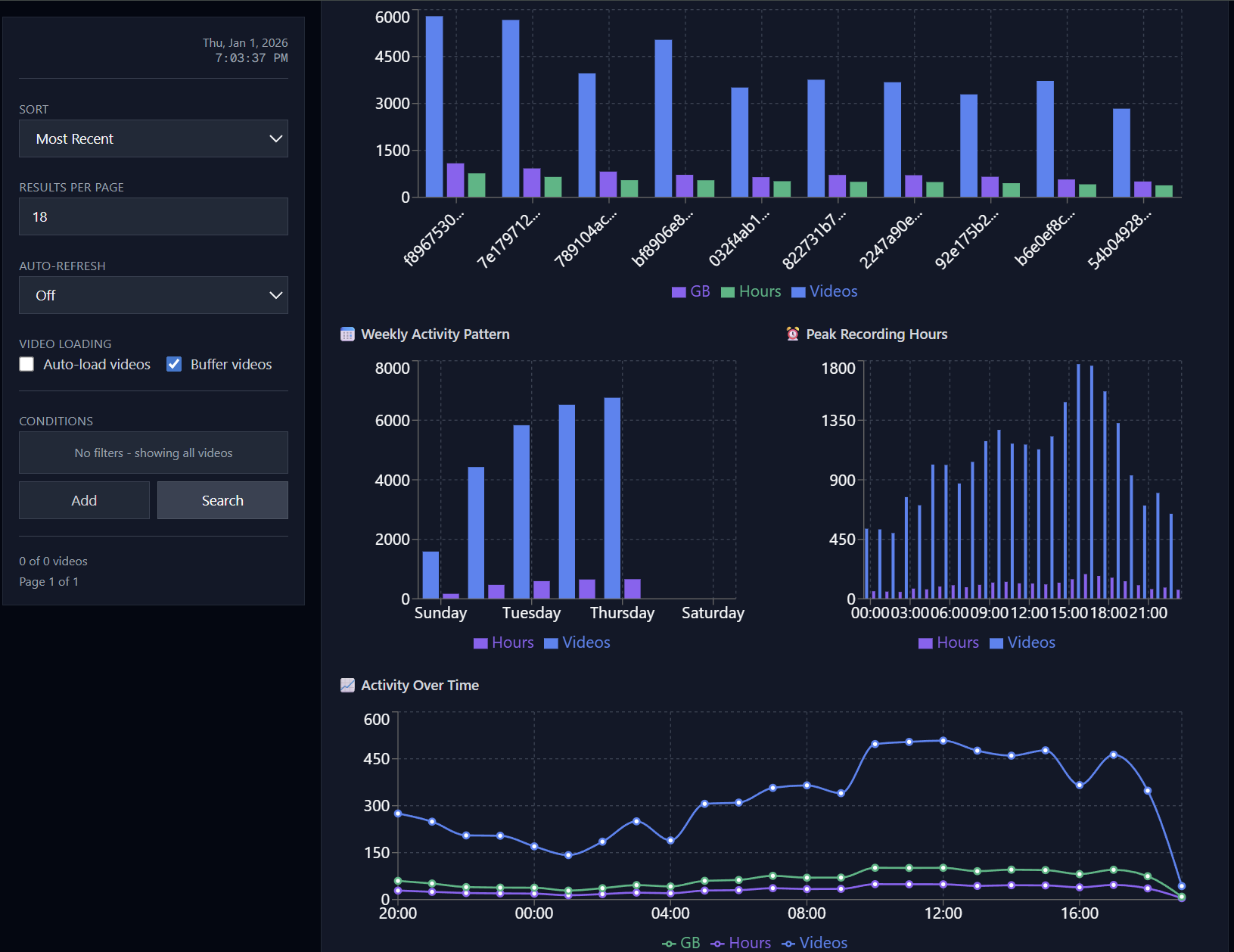
OWL Control and OWL Tube were written to solve this problem. OWL Control is an open-source desktop application that captures gameplay footage and inputs, tracks sessions and users, and uploads the game data to our storage and the session information to our database. OWL Tube is our monitoring tool. It’s the view from our side; a video streaming and analytics platform for browsing and verifying the collected data. Together, they’re our data collection and verification pipeline.
By The Numbers: Data
- 21,143 hours (1.26 million minutes) of game footage
- 191,282 recordings
- 28.22 TB of storage
- 210 contributors
- 8 months
- 399 different games
- 99% of recordings have complete metadata (189,368 of 191,265 files)
These are a little approximate because we’ve averaged about 5,000 uploads a day for the most recent week, so it will have moved while composing this post.
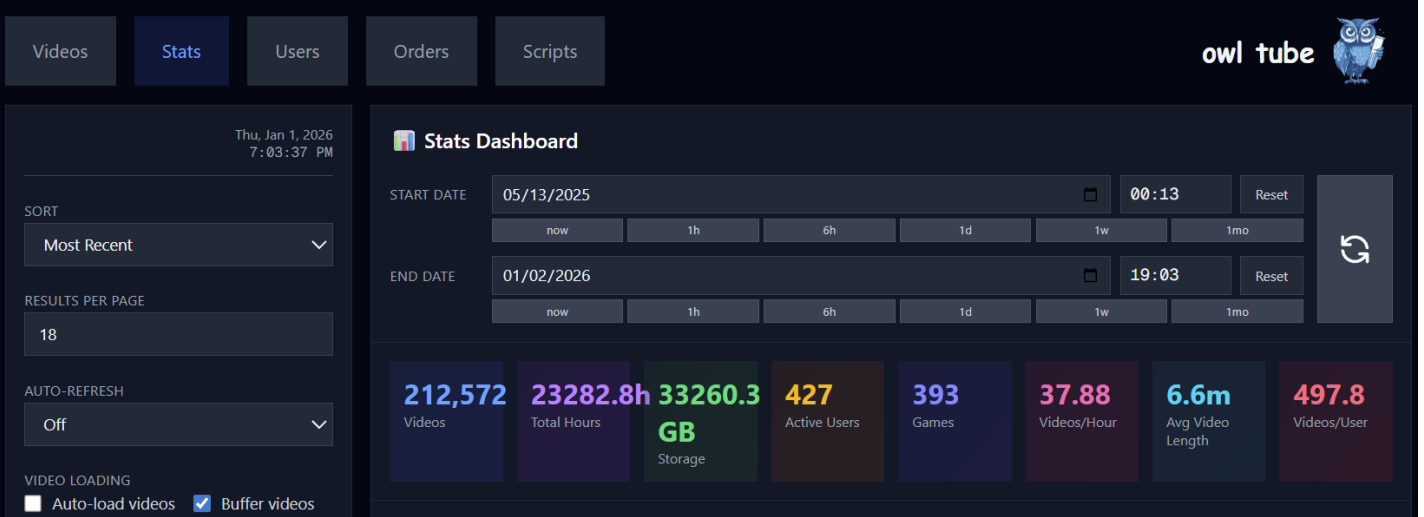
By The Numbers: Scaling
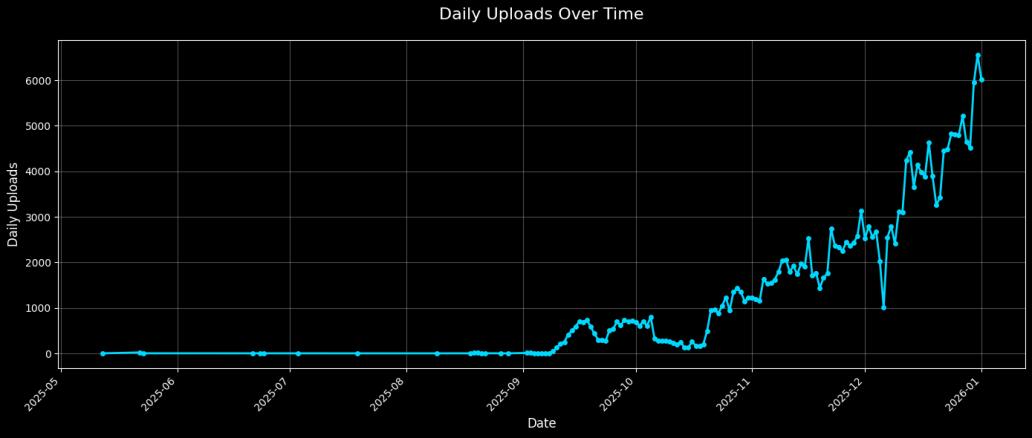
Data collection ramped dramatically over our nearly 8 month period of active collection, starting with our first upload in May 2025 and scaling up in August 2025.
- August 2025: 10,435 uploads, 71 users, 1,391 hours
- September 2025: 19,470 uploads, 67 users, 2,619 hours
- October 2025: 58,168 uploads, 137 users, 6,433 hours
- November 2025: 103,137 uploads, 146 users, 10,700 hours
- December 2025: 116,449 uploads, 228 users, 12,057 hours
We averaged about 1,427 uploads per day across 134 active upload days. Most recordings were 5-10 minutes of gameplay (100-200MB files), with only 53 (or 0.03% of recordings) exceeding 1GB.
What Worked
Some of our choices worked out great! We’d like to make sure we remember what those were so we can continue to improve our process and do it better in the future.
Rust
Rust, for lack of a better word, is good. Rust is right. Rust works.
Initially, OWL Control was an Electron app. This made perfect sense for an initial prototype, and became unwieldy the longer we were maintaining it. Making the system hooks we used to record gameplay work was awkward, the build path was convoluted, our upload logic was tricky to get right, and we just had so, so many libraries to keep track of.
Rust made this one build, in one language, that nicely handled the client UI, complicated upload logic, and all of the system hooks for recording. If your desktop app does something that has a lot of tricky system logic to it, it’s hard to see how Rust wouldn’t be the best choice. Our primary regret about Rust is that we didn’t use it more and sooner.
libobs-rs
Our collaboration on libobs-rs was a huge help, and we’d be happy to work with the project again. OWL Control’s Rust port was made possibly by libobs-rs and its primary maintainer, sshcrack, who was exceedingly helpful and responsive to our requests. We've sponsored him, and we encourage the use of libobs-rs if you need a programmatic way to record gameplay. This was not the first method of recording we tried - it ended up being by far the best.
Wise
International payments are tricky. After trying to work with a kludge of other payment methods, Wise was by far the most hassle-free, and we ended using them exclusively. Other payment processors, by and large, do not seem to understand what you are doing if it’s unusual, and when payment processors are confused they tend to want to hold payment or make you do extra paperwork. Wise avoided needless hassles and worked reliably.
Stack-Auth
We use stack-auth for authentication, and authentication just works. It is honestly hard to figure out what else to write about that. We used them from the start and authentication has never been a problem for us. ‘nuff said, probably.
OWL Tube
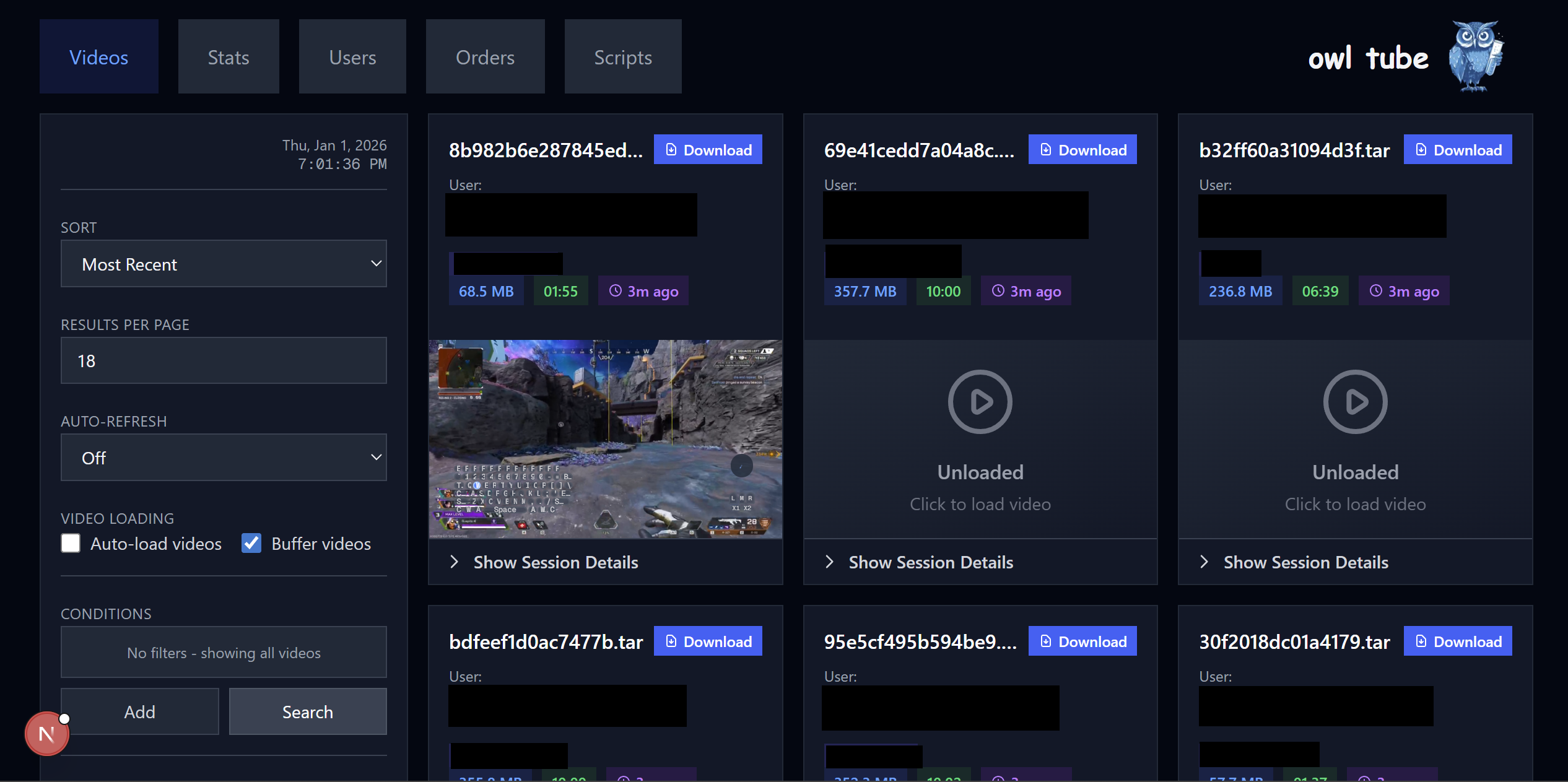
OWL Tube is our flow for analytics and verification of uploaded data. It’s the dashboard we use to see what we have, what we’re getting, and what we might want to change. It has to track uploads, track users, and make sure we have enough information to track outgoing payments for users. Fundamentally it works, and hasn’t been a major problem, even though it was done in sort of a hurry.
One of the key factors here is how many users it has: OWL Tube’s users are us, and there are fewer of us than there are users. This meant that the growing pains with scale that we had on our user-facing API just weren’t as much of a factor. For internal tools like this in particular, just hurrying up and shipping it was actually the good choice. If we had it to do over, we’d build this out more and faster, but we probably wouldn’t change any of how we made it.
What Broke
When you’re moving fast, you expect to only get your must-haves and almost never get your nice-to-haves. If you have ten nice-to-haves but only one of them will turn out to be a serious problem later, it is often actually better to do none of them and wait to see which one matters later. Drawing the line is tricky, though, and some of these should probably have been considered must-haves.
Documentation, Design & API Contracts
We didn’t write a lot of our early decisions and assumptions down and we didn’t have much of a process for keeping track of later ones as they were made. This was completely fine when we were smaller, both at the user and employee level, and became much less sustainable over time. Once we were operating at scale, any decision we’d ever made could become a bottleneck, not everyone necessarily knew what they were, and any new decision could have ripple effects on the rest of our stack.
This lead to a few problems: For one, when we had resource bottlenecks, it wasn’t always clear where to even look for the issue. The design on a given workflow was not written down and the assumption that was no longer true. “This table has no more than ten thousand items in it” wasn’t a specification or written anywhere. For another, when we tried to make changes (e.g., allowing 720p recordings) we didn’t have documentation for this. We didn't all know our infrastructure assumed 360p or what all we would need to do to actually process data at 720p.
Going forward, we’d like to try to make sure we have design documentation that sets out our API contracts, data formats and other assumptions. If we keep that spec alive and up to date as we make changes, we can hopefully have less friction in the future.
Data Validation
We didn't build ways to check if our recordings were actually good until we'd already collected a lot of bad ones. Input desync, cropping issues, distribution problems—all of these sat in our dataset for months before we noticed. (We managed to fix the desynced data, but we’d rather have not had this problem at all!) Users were uploading hours of footage that our preprocessing would later reject, and they had no way to know until it was too late.
When we finally added metadata visibility to OWL Tube and better client-side validation to OWL Control, we could actually see problems as they happened instead of discovering them weeks later during processing. Data quality improved immediately.
If we had this to do over, we’d have made data validation a higher priority on our end. If you're collecting data at scale, you need to be able to see exactly what you're getting in detail while you're getting it. Build your dashboards and validation checks early.
Scaling Pains
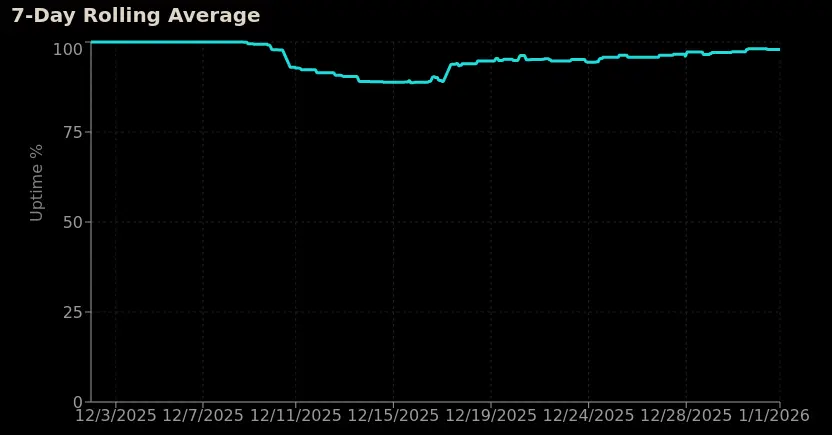
Our backend Python API started as a prototype and mostly stayed that way while handling production traffic. Our largest issue was that it had badly-scaling queries that tended to hang, which caused most of our outages. Uptime started okay, and then hovered around 85–90% for a while once it was under load, which was absolutely not viable. Eventually it climbed to ~97% once we added proper logging and monitoring so we could find and fix our resource bottlenecks. (Also, because we had no test environment, everything got tested in production.)
We also had issues with our upload speeds internationally, and our attempts to mitigate these mostly did not work. We spun up infrastructure in Asia pacific, but load balancing missed it, leaving this entire node for API service orphaned, and the ultimate bottleneck wasn’t our API but the actual upload step to our object storage, which was, stubbornly, in North America. Ideally we’d consider the geographical distribution of our users more closely and earlier during our infrastructure spin-up.
We kept patching it because a rewrite or overhaul seemed expensive. In retrospect, the overhaul would have been cheaper months earlier. Since we’re expecting to slow down on how much data we ingest going forward, it’s the perfect time to try to do things the right way instead of the fast way. This means decoupling unrelated services, being careful of resource bottlenecks, and more work put into observability, test environments, and CI/CD.
Support
We didn't have a ticket system. Developers got DMed constantly. There were countless support requests, payment issues, bug reports… all of it. Our external OSS contributor got pinged with API and payment questions he couldn't answer.
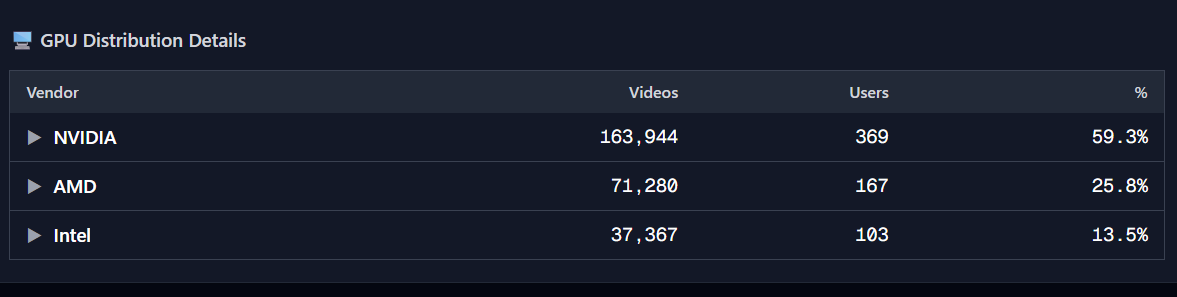
The hardware diversity issue made this worse. We were supporting contributors with wildly different setups, including some 15-year-old machines, which generated endless long-tail bugs. Without a ticket system, we couldn't even track which hardware issues were common versus one-offs. Every debug session was isolated, so we'd solve the same problem multiple times without realizing it.
Lessons
Call this a longer version of the TL;DR.
We probably should have done these things earlier:
- Written down our data format and API contracts
- Had a pipeline for validating our data as it came in
- Set up a ticket system to make support more organized
- Set minimum hardware requirements
- Caching, especially for authentication
- Swapped payment over to Wise, and the client over to Rust
We were probably right not to do these things earlier, but we really ought to do them now:
- Overhaul our API, maybe moving it into Rust, not even because it’s faster than Python but because it is easier to reason about its resource use
- Add proper CI/CD so we stop testing in production
- Decompose services to contain failures and give different services different resource budgets
- Set clear boundaries for developer availability and route support through official channels
Why Share This
If you’re scaling a prototype or building data infrastructure, hopefully this is helpful! There’s a pretty wide gap between “it works on my machine” and “it works for everyone”, and it’s actually pretty tricky to figure out which things are important to get in front of early and which things just aren’t.
Hopefully documenting the process and details in the open is helpful. If you're working on similar problems or want to discuss infrastructure and data pipelines, join our Discord or check out our open positions.