
Prompting Guardrails and the Shape of a World
When someone types the word “castle” into a text-to-image model, they get a castle. The mapping is direct. World models work differently.
Overworld’s model doesn’t take “castle” as input, but instead expects something closer to a short video clip paired with aligned controls. That’s what it was trained on and the distribution it understands. Therefore, a single word is too underspecified. Structured interaction is the native interface of a world model, not text.
There’s a large gap between what a user types and what the model expects. This week’s blog post digs into how we build a system to close that gap and what it taught us about safety, bias, interaction design, and the model itself.
The Sanitizer (Before It Was a Pipeline)
We weren’t thinking about experience design from the get-go. We were thinking about guardrails. If you’re deploying a world model product, you need a way to:
- Prevent banned content (explicit material, celebrity likeness)
- Avoid recreating recognizable branded properties
- Keep generations within the distribution you trained on
Our solution was to build a sanitizer. The early version was straightforward. A user would type something, and then the sanitizer would examine it, rewrite it if needed, and pass along a modified version that complied with our content guidelines.
For example, if someone referenced a popular game, the sanitizer would transform that into something aesthetically similar but nothing derivative of a specific title. The model could technically produce something much closer to the requested game, but we chose not to let it.
This was the original purpose, but the sanitizer quickly became something even more important.
From Text to Structure
Our model doesn’t have strong text-to-image capabilities because it doesn’t need to. What it needs is:
- A structured prompt
- A seed image aligned with the training distribution
- A short synthetic video
- Control signals aligned to that video
So, the pipeline evolved. If a user types, “castle,” the system performs several functions, including:
- Rewriting and enriching the prompt
- Generating a seed image aligned with the model distribution
- Extending it into a short video
- Passing that video through an inverse dynamics model
- Producing aligned control signals
- Feeding everything to the world model
To make this concrete, below are two examples using the same structured prompting process applied to two different environments. In both cases, the 3x3 grid displays the evolution of a generation through distinct stages of the pipeline: the initial seed image, the synthetic video extension, the IDM-aligned controls, and the final interactive world model output.
The first example utilized the prompt, “driving a motorcycle on Cyberpunk Mars.”

From that single sentence, the system constructs traversal dynamics, velocity-aligned camera motion, and environmental coherence. What begins as a seed image becomes structured video, then aligned control signals, and finally an interactive riding experience.
This second example utilized the prompt, “traveling through a spooky forest. Ominous figures walk around.”
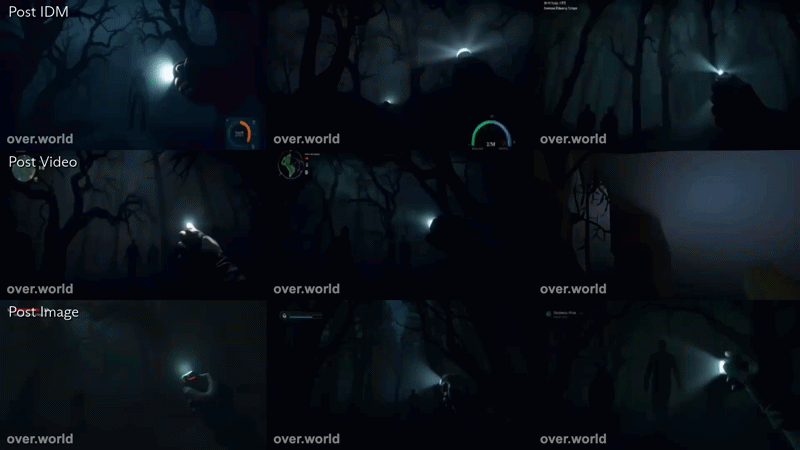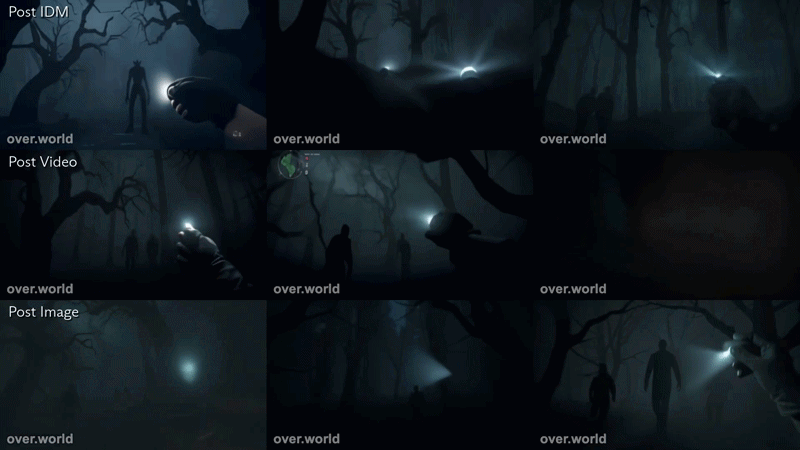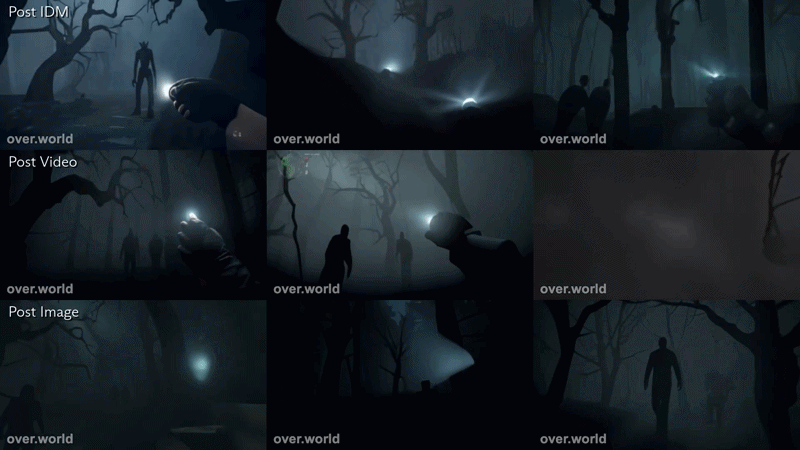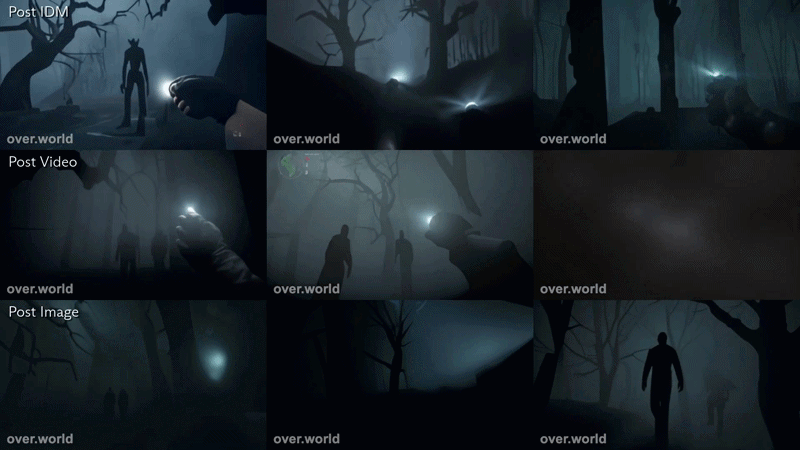
Here, the same pipeline produces a low-light, atmospheric traversal sequence. Fog, shadow, and ambient agents are introduced during video synthesis, then grounded through control alignment to maintain interactivity rather than passive continuation. In both cases, the structure is identical. The environment changes, but the pipeline does not.
All the user needs to do is type one word, and the pipeline constructs an entire experience. This is where something subtle happens.
If we passed only a video into the model, it often interpreted that video as a cutscene. It saw it as something to continue, but not something to interact with. The model would generate forward, but responsiveness would drop. The world would feel passive, but aligned controls change that.
By pairing IDM-derived controls with generated synthetic video, we condition the model on the fact that this world is interactive. Acceleration curves, mouse sensitivity, and interaction triggers all become part of the conditioning.
If a user then says, “When I press F on a casket, I get a new weapon,” we render more than a casket. We generate a sequence where a casket opens, an inventory-like state appears, and that behavior is embedded in the aligned controls.
The model learns the rule, not just the aesthetic, and prompting becomes lightweight gameplay scripting. These are part of the conditioning distribution, where the IDM aligns the button press with the visual transition.
At this point, the deployed product is more than the diffusion world model; it’s the pipeline plus the world model as a unified system. The structure layer is inseparable from the generative core.
What Users Actually Want
Once the pipeline went live, patterns started to emerge. Two dominant themes came to the forefront almost immediately: horror (eerie forests, abandoned warehouses) and driving (first-person car perspectives through varied terrain).
This wasn’t random. The model was already good at camera motion aligned with forward velocity and low-light effects, fog, smoke, and fire. Users gravitated toward the model’s strengths before we fully mapped them ourselves. Then the failures started to show up.
The first example was when users were prompted that they were holding a gun in first person. The model would often point the gun toward the camera or hold it parallel to the lens. From the model’s perspective, that made sense. It had seen guns before, just not consistently as first-person attachments extending from the player’s body. It didn’t understand held objects as embodied extensions of an agent. That was out of distribution.
Without the prompting pipeline surfacing these patterns at scale, we wouldn’t have diagnosed this nearly as quickly. The sanitizer became our measurement tool.
Why We Didn’t Wait for “Prompt Culture”
In early diffusion, users built a prompting culture organically. People discovered that “golden hour,” “8k,” or “trending on ArtStation” reliably shifted outputs. Communities formed around these token tricks. It took months, but the ecosystem self-optimized. This approach doesn’t work here. This technology is too frontier, and the distribution gap is too large.
If a user types “castle,” they’ll get something that looks like a castle. With structured input, the world model is capable of an adventure with courtyard traversal, hedge mazes, drawbridge crossings, and encounters. However, the user doesn’t know to ask for that structure.
We didn’t want to wait months for best-practice guides, so we made a decision to jump into assumptions. If you type “castle,” we assume you want to experience traversal, progression, and interaction. That introduces a small amount of friction, and the pipeline rewrites your prompt and enriches it. In exchange, the world model performs at the capability frontier from the first time.
Mid-Sequence Control and Rollback
Once prompting becomes structural, it doesn’t have to be static. When the world state is conditioned on structured inputs, we can explore:
- Prompting mid-sequence to change objectives
- Modifying interaction rules dynamically
- Rolling back to previous prompt state and branching
- Re-generating segments with different control assumptions
If a user decides they don’t want to walk into the castle, but instead want to fly over it from a dragon’s perspective, that shift can be represented as a structural update instead of a full reset. As we continue to iterate on both the model and the pipeline, this kind of dynamic reconditioning becomes increasingly feasible.
The Bias Problem
If users mostly generate driving scenarios, and we tune the pipeline and post-training toward driving, the model gets even better at driving. Then, the user prefers driving, the feedback loop tightens, and this introduces bias toward popular interaction types.
Helicopters, underwater exploration, space traversal, and surgical simulators can get relatively less attention if we aren’t careful. So, we actively counterbalance by using prompt distribution. This doesn’t just reinforce strengths, but it maps gaps. If something is underrepresented but strategically important, we curate for it explicitly. The pipeline gives us the distribution map, and our job is not to blindly follow it.
Closing the Loop
The most important thing we learned is that prompting is more than UX. It is model alignment, safety enforcement, interaction design, and training data discovery, all at once. Every generation updates our understanding of what users want, what the model is good at, what it misunderstands, what is in-distribution, and what needs curation. Over time, this allows us to improve responsiveness mid-sequence, enable re-rolls of structured experiences, support prompt modifications and rollbacks, and expand scenario coverage before users explicitly demand it.
The world model isn’t a standalone artifact, but rather a world model and a prompting pipeline acting as one system. The pipeline translates intent into a structured signal, and the model turns the signal into experience. As that loop tightens, the distance between imagination and interaction shrinks. That’s the real goal.
If this excites you and you want to come work with us, we’re always hiring. Click here.