
Optimizing World Model Inference Speed with Quantization
TL;DR
At its heart, the post tackles a critical bottleneck in large-scale transformer-based generative models: the KV cache. During inference, this cache stores the context from previous steps, but it can grow very large, consuming memory and hitting bandwidth limits as data is repeatedly read by the GPU.
Our core strategy is to store the cache at a lower precision (8-bit) while keeping all activations and math in high precision (BF16). We dequantize the cache just-in-time, and thanks to torch.compile, the overhead of this process is near-zero once the kernels are fused. This reduces memory pressure while preserving numerical stability.
Another key detail is that Keys are far more sensitive to precision loss than Values. An error in a Key can derail the attention "lookup," while an error in a Value just slightly degrades the final output. Our robust default is therefore to keep Keys in BF16 and quantize only the Values.
Finally, we complement this with TorchAO MX formats for linear layers to improve GEMM bandwidth, and we rely on PyTorch FlexAttention for the underlying attention implementation.
A Refresher: The Roles of Q, K, and V
In the self-attention mechanism, three vectors are derived from each input token:
- Query (Q): Represents a token's current state, used to initiate a lookup. It effectively asks, "Given who I am, what context is relevant to me?" Its shape is [Batch, Heads, T_q, Dim_head]. In the context of video generation, this is often a block of patches (e.g. an entire frame).
- Key (K): Acts as a label or address for a token that can be "looked up." It's compared against the Query to determine relevance. Its shape is [Batch, Heads, T_kv, Dim_head].
- Value (V): Contains the actual content or information of a token. This is the information that is retrieved and aggregated. Its shape is [Batch, Heads, T_kv, Dim_head].
The attention operation uses the Query to calculate a similarity score with every Key in the context. These scores are normalized into weights, which are then used to compute a weighted sum of all the Values. The result is an output vector with the same shape as the Query, but it has been transformed from an isolated representation into one that is enriched with information from the surrounding context.
Why Precision Matters: The Sensitivity of Softmax
The decision to quantize V while keeping Q and K in high precision isn't arbitrary; it stems from the two-step nature of the attention mechanism:
Scoring (softmax(Q @ K.T)): The softmax function is highly sensitive because it involves exponentiation. Even tiny errors in the Q or K vectors can be amplified, leading to incorrect attention scores. This could cause the model to focus on irrelevant parts of the context, destabilizing the output.
Aggregation (... @ V): Once the attention scores are locked in, the model simply computes a weighted average of the V vectors. A small amount of noise in the V vectors is much more forgiving; it might slightly degrade the quality of the retrieved information, but it won't fundamentally change what the model is attending to.
The Magic of torch.compile: Eliminating Overhead
A key question is whether the process of dequantizing from 8-bit back to BF16 for every attention computation is slow. Naively, it could be. An un-optimized approach would involve multiple slow trips to the GPU's main memory: load the int8 data, load the scale, compute the bf16 result, write that intermediate result back to memory, and then load it again for the attention calculation.
This is where torch.compile becomes essential. As a Just-In-Time (JIT) compiler, it can perform an optimization called kernel fusion. Instead of running many separate operations, torch.compile fuses them into a single, highly efficient GPU kernel. This single kernel loads the int8 data and its scale, performs the dequantization on-the-fly inside the GPU's fast local registers, and immediately uses the result in the attention math.
By eliminating the slow memory round-trip, the overhead of dequantization becomes negligible. This makes the "store low, compute high" strategy practically free from a performance standpoint.
A Minimal API Sketch
To make these concepts concrete, here is a look at the core implementation. The goal is to create a quantized cache that can be used as a drop-in replacement for a standard one, hiding the complexity from the model's attention logic.
The core logic is handled by two helper functions that perform the quantization and dequantization using per-token scaling:
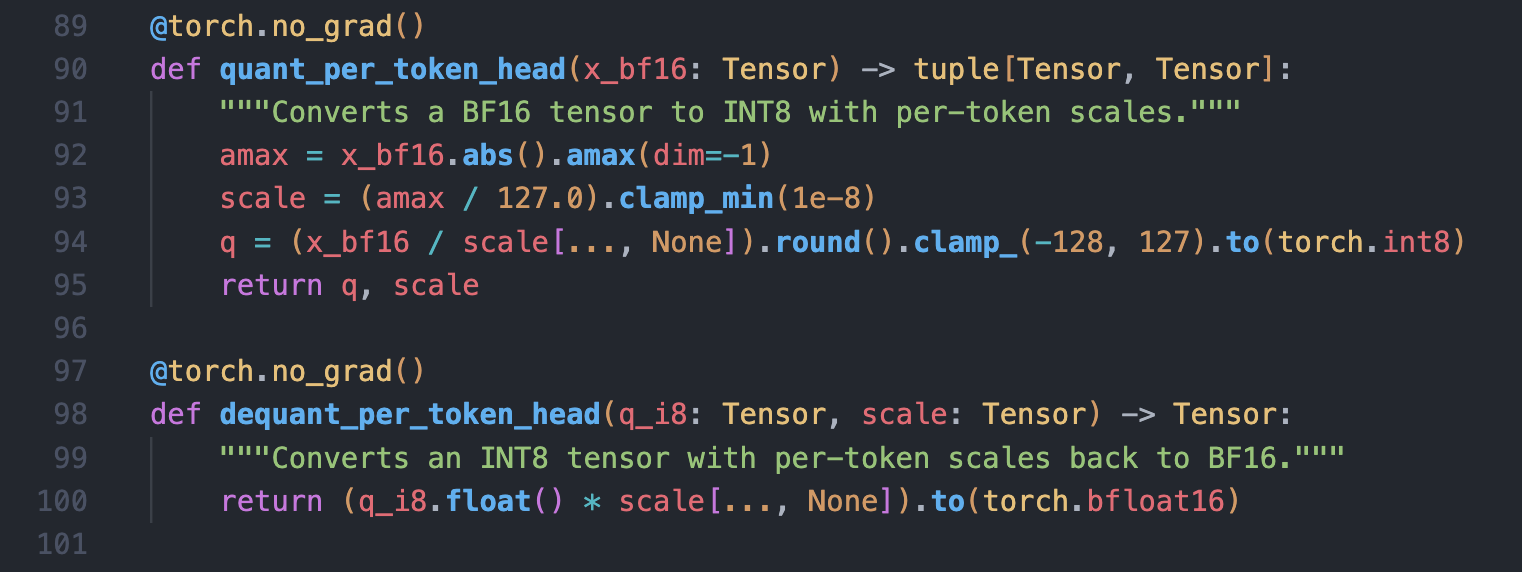
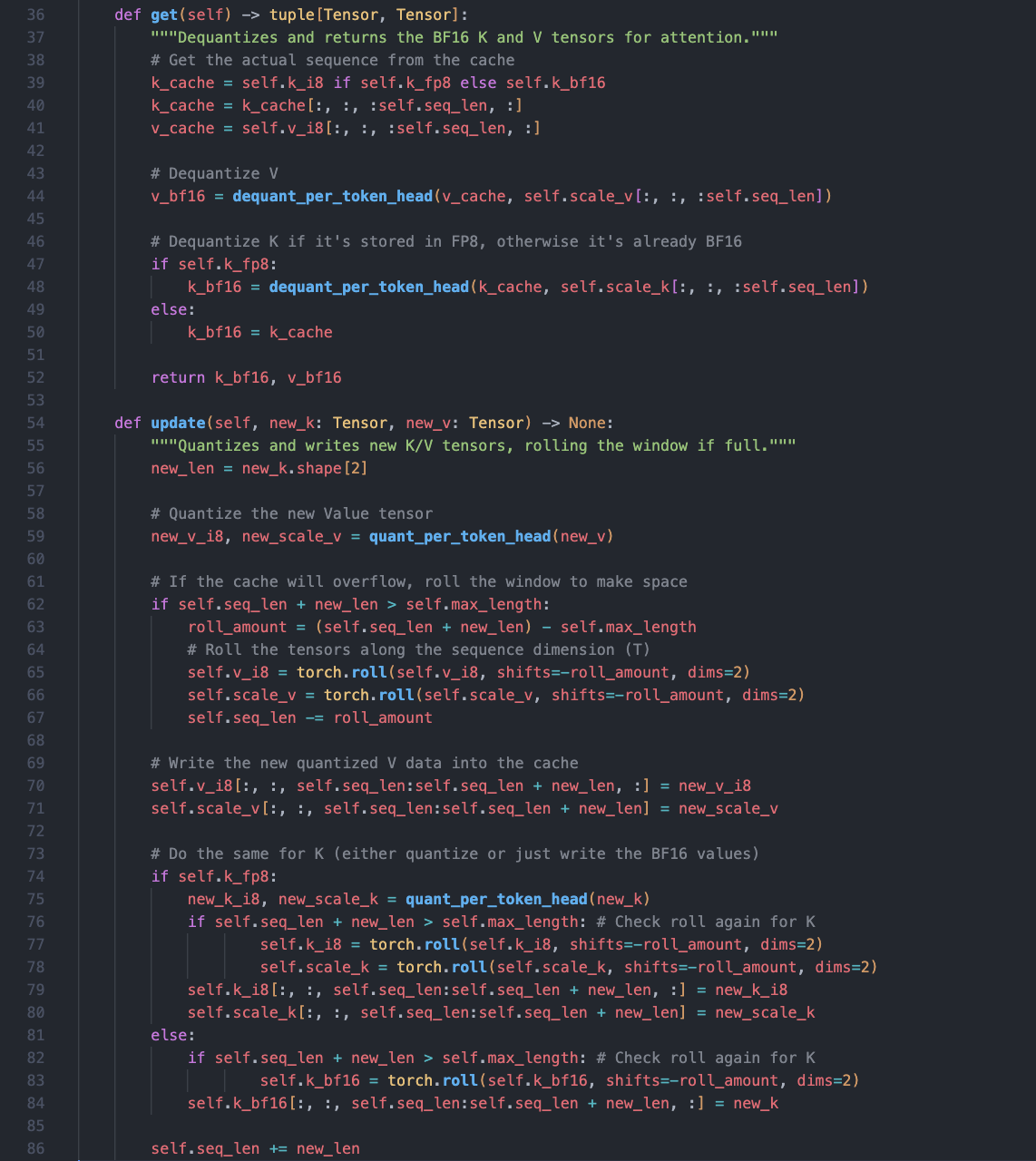
These helpers are used within a cache class that abstracts away the de/quantization logic. The .get() method always returns high-precision BF16 tensors to the attention layer, while the .update() method handles the quantization for storage.
Boosting Performance with MXFP for Linear Layers
Separate from the KV cache strategy, we can use MX formats (like MXFP8 and MXFP4) for nn.Linear modules. This is a complementary optimization that targets a different part of the model: the large matrix multiplications (GEMMs) in the feedforward networks and the QKV projections.
Unlike the KV cache approach, MX is often a "store low, compute low" strategy, where the math itself is performed in a low-precision format. It's a powerful technique for improving the throughput of these linear layers.
However, the end-to-end gains from MX are "modest" for their specific workload. This is because the primary performance bottleneck is the attention kernel and memory bandwidth, not the linear layers. Speeding up a part of the model that isn't the main bottleneck provides a welcome, but not dramatic, overall improvement.
Fine-Tuning Performance
Beyond the default settings, several advanced techniques can be used to push performance further, each with its own trade-offs:
- Late-Layers K-FP8: While quantizing Keys is risky due to softmax sensitivity, applying it only to the final layers of the model can be a viable trade-off. The intuition is that early layers learn fundamental features where precision is critical, while later layers handle more abstract concepts and may be more robust to slight numerical noise.
- Per-Channel Scaling for Keys: Instead of using one scale factor for an entire token vector (per-token), this approach calculates a separate scale for each individual channel (or feature dimension). This preserves precision much better when a vector contains values with widely different ranges, preventing small but important features from being wiped out by large ones.
Percentile Scaling for Values: To guard against outlier values, this method calculates the scale factor using a high percentile (e.g., 99.5%) instead of the absolute maximum value. This prevents a single anomalous spike from "squishing" the numerical range of all other values, leading to a more stable and robust quantization of the V cache.
Open Issues & What’s Next
Our work on quantization is ongoing, and we're actively exploring several promising directions to further improve performance and efficiency:
- Fusing Dequantization with Attention Loads: Our current implementation dequantizes the 8-bit cache into a temporary BF16 buffer before the attention calculation. A key next step is to explore a fully fused kernel that reads the 8-bit data directly, performing the dequantization on-the-fly. This would eliminate the intermediate buffer and further reduce memory traffic.
- Leveraging TransformerEngine KV Kernels: We're closely evaluating a move from our current "int8+scale" software emulation to using NVIDIA’s Transformer Engine (TE). This would allow us to leverage the dedicated hardware FP8 support in newer GPUs like Hopper and Blackwell. The main task will be to measure the performance gains against any potential changes in numerical behavior.
- FlexAttention: The performance characteristics of the prefill (initial prompt processing) and decode (token-by-token generation) phases are very different. We continue to track improvements in PyTorch’s FlexAttention and its JIT capabilities to ensure it always selects the most optimal kernel for each phase of inference.
Ring Buffers: We experimented with ring buffers—a theoretically faster method for managing the KV cache that avoids large memory copies. However, we find that its "dynamic indexing" (a constantly changing write position) caused issues with torch.compile, leading to instability. We opt for the simpler "roll-window" approach.
This exploration would not have been possible without the contributions and discussions of Fluffy from Eleuther and Alex Redden!
If you'd like to help with any of these projects or join in on the lively discussions that actively take place on our Discord server, please join here! While you can join as a volunteer whenever you'd like, we are also taking applications for full-time positions here.